Bandwidth’s Research & Development (R&D) team explores technologies that may be relevant for our CPaaS customers, providing new revenue streams and incremental value to existing service offerings.
Our team built the prototypes for now-in-production services such as 2FA, WebRTC, as well as the current infrastructure running our updated hyper-scale messaging services (SMS/MMS). R&D projects can range from a single integration with a backend billing queue, to facilitating new revenue streams by building iOS apps and backend services to speed the on-ramp of major customers. (If you’re interested in being a part of this great team, check out these open positions!)
We also occasionally jump into projects with no relationship to Bandwidth’s core products. These side projects allow the R&D developers to stretch their wings, learn new technologies, and have some fun. For example, we occasionally design and 3D-print swag for Bandwidth’s event booth.
So it was in mid-2021 when a colleague casually mentioned the AWS DeepRacer competition and asked if anyone in R&D was working on an entry for it. After some review, we decided to invest some developer resources in exploring reinforcement learning for the remaining 3 months of the racing season. The ultimate prize is a seat at the 2021 AWS DeepRacer championship held at the yearly AWS re:Invent developer conference.
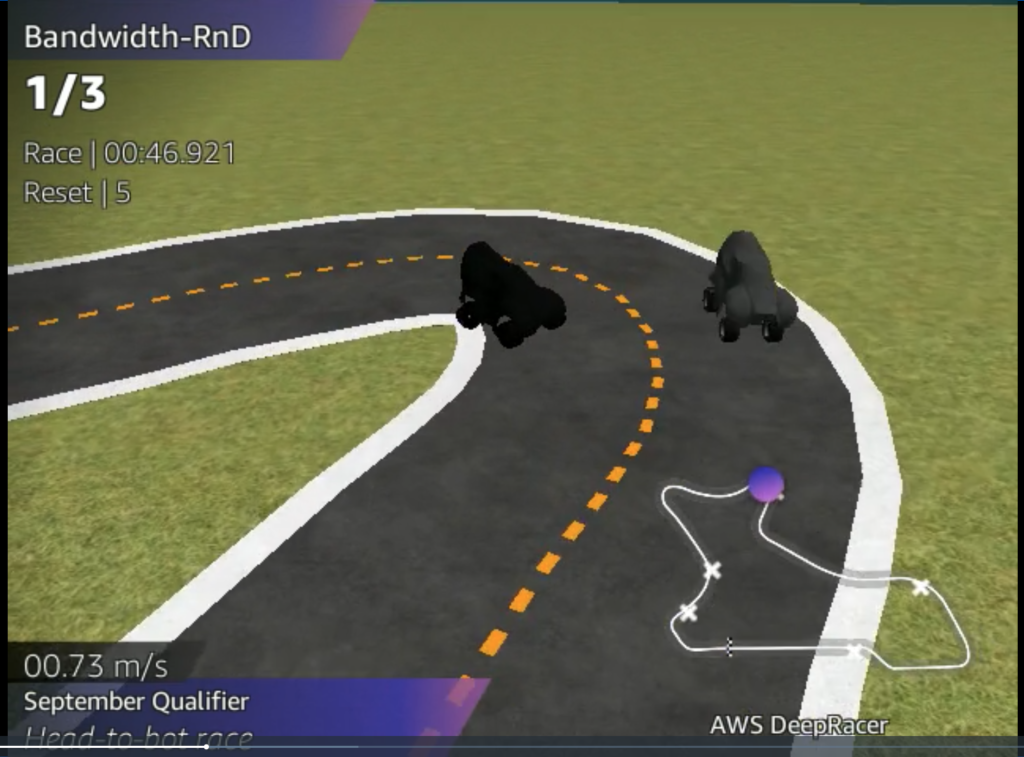
AWS DeepRacer
DeepRacer is a reinforcement learning playground that models a car driving around a track, including 3D rendering the scene from the car’s perspective, and providing add-on challenges such as object avoidance or head-to-head racing.
A unique feature of DeepRacer is that the platform was designed to enable Sim2Real; the ability to take a model trained in the simulator and run it on a small AI driven race car around a real-world track. This unique aspect adds additional depth and interest to the challenge and provides participants with visceral feedback as they watch their model veer off the track and crash into barriers.
The DeepRacer platform is structured around two main components: a simulator for a virtual environment and a machine learning framework. The participant has no control over the simulator or other physical constants. The machine learning framework has a few options available such as choosing between continuous-vs-discrete model outputs, using a shallow or deep neural network, and various hyperparameters to adjust learning.
While AWS provides a console for training through SageMaker, a community of enthusiasts have been able to extract the simulator and training materials, hosting them on custom EC2 instances for “offline” training. Since any number and size of EC2 instances can be launched, this method allows more control over the training costs and time.
Our R&D team used this framework for training our racers—the amount of work put into these tools and the community support available are unparalleled in our experience.

Reinforcement learning
The “AI brain” of the DeepRacer car is provided with an image from its front camera [figure] about 15 times per second, from which it must select the desired acceleration and the desired steering angle. This control scheme is deceptively simple, as there is no other input to the model, all navigation knowledge must reside in the model parameters (its “memory”).
AWS has chosen to restrict the racer’s training algorithms to use reinforcement learning, where participants can only influence the racer’s training by providing a single number score for each step of the simulation. This number is expected to be near-zero when the racer is performing poorly, and arbitrarily large when the racer is performing well. A given run of the racer on the track is considered better if its total score (the sum of each step’s score) is higher than some other run. This simple goal is why Reinforcement Learning is the technique most often used when training computers to play video games, such as Google DeepMind training an Atari game playing engine.
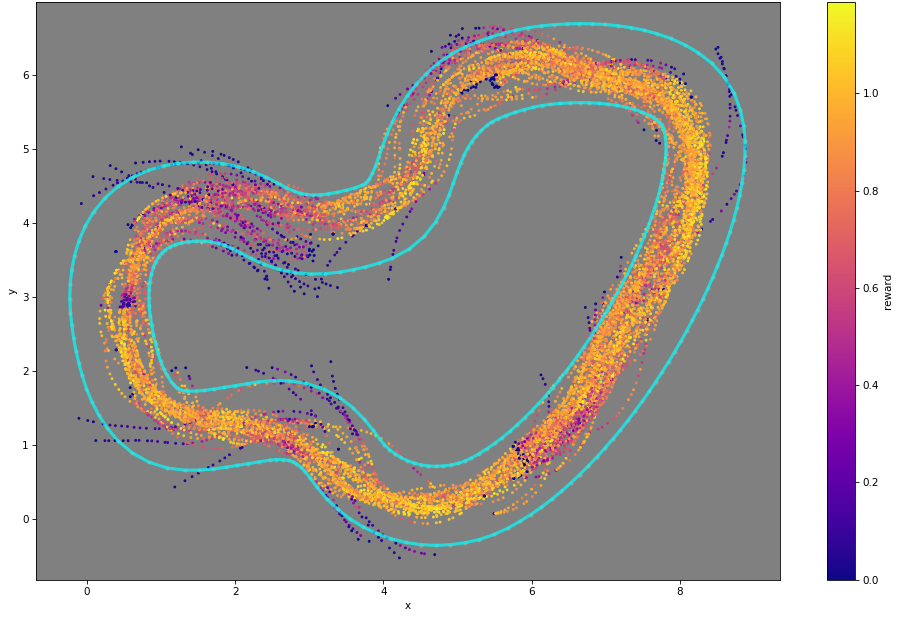
Reward function
The participant provides this score by implementing a “reward function” which is called after every simulation step to generate a score for the current situation. The DeepRacer simulator provides a bucket of useful parameters to the reward function to use in its decision making, such as the racer’s coordinates on the track, waypoints along the centerline of the track, current velocity, steering angle, etc. Note that none of this information is available to the model during a race, which receives only the image from the front-facing camera.
Since this is the only way to influence model training, the core challenge of DeepRacer is in designing and implementing the reward function and selecting among the various hyperparameters to use during training.
Prior art
In the initial sweep of analysis, we located several common themes for reward functions described by other participants from years past. We were able to leverage our domain knowledge in ML to quickly eliminate the majority of these recipes, leaving just a few existing solutions for further analysis.
The existing solutions we implemented and tested included:
- Bonus for Lap Completion
- Optimal Driving Line
- Steer-to-Centerline
Our first month was dedicated to testing these solutions, while building tooling to speed the process of vetting reward functions without the overhead of training a new model.
Bonus for lap completion
The idea behind ‘Bonus for Lap Completion’ is to get the racer around the track using some other technique, then provide a large reward whenever it completes a lap. It is assumed that this large reward will encourage additional lap completions, creating a self-reinforcing cycle of learning.
After thorough testing, we did not find this strategy to be effective. It is our belief that the end-of-lap reward is too sparse, requiring extremely long training times to achieve good results. This additional training time could be better allocated to reward functions that improve consistently during training.

Optimal driving line
The ‘Optimal Driving Line’ is a much more complex strategy, requiring significant offline resources to extract the track waypoints, implement an algorithm to locate a near-optimal driving line (one which cuts to the inner lane around hairpins), and modeling the virtual racer along this line to find a near-optimal speed and turning angle (one which avoids skidding on tight turns at high speed).
This is a known-successful strategy employed by all major racers. We implemented this strategy, finding improvements to the line optimizer, and precisely modeling the correct speed and turning angle at each point along the raceline.

As expected, this strategy provided high-ranking performance for the basic track traversal challenge, easily placing us in the top 20% of participants. Since this is a well-known technique, many other advanced developers also employ it, and breaking into the top 10% requires more work. This strategy is not applicable for the other two pro-circuit challenges; head-to-bot racing and object avoidance, since the optimal race line would be different for every run.
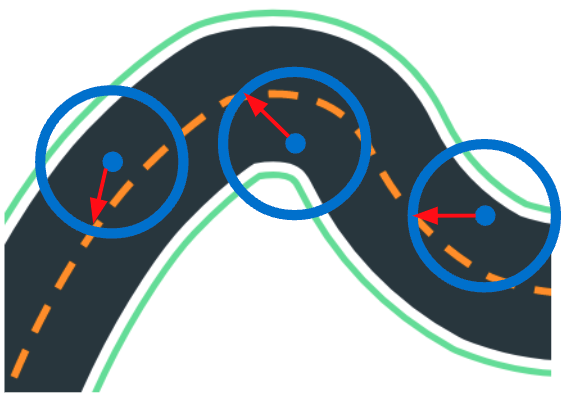
Steer to centerline
Finally, we also tested the “Steer-to-Centerline” strategy, one of the simplest we found. Here, the reward function picks a point slightly ahead of the car’s current position, chooses the waypoint closest to it, and rewards the model for steering its wheels toward that point. (Note that this differs from the AWS-supplied example function “Follow-the-Centerline,” which rewards the model for distance from the centerline, regardless of steering angle.)
Amazingly, this simple strategy was the most effective of all the prior-published techniques in achieving lap completions. The strategy is so successful that it takes only a few tens of iterations to get a new model around any track!
In our testing, we found an unfortunate Achilles heel hidden within this strategy. After completing a lap at some speed, the car consistently improves its lap completion rate at the expense of ever-slower speeds. Ultimately, the car achieves 100% lap completion at the slowest possible speed. After some analysis, we found that the racer cannot improve its overall score by completing laps faster; since it is rewarded per step, going faster around the track offers fewer steps, thus lowering the total reward. So the AI diligently works to achieve the highest score, which requires taking as many steps as possible to go around the track.
With such strong initial performance, we knew the steer-to-centerline strategy was the way forward for new models, but some other technique such as following an optimal race line would be needed to pierce the top 10% of competitors.
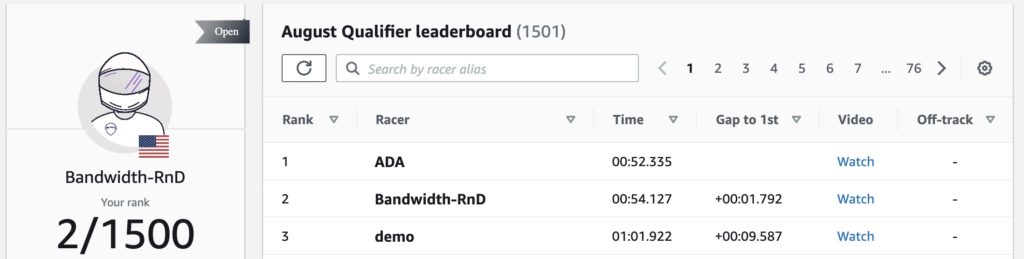
Entering the Pro Circuit
Participating in the amateur division for the first month, we earned 2nd place in a field of 1500 competitors and gained access to the pro circuit. It was time to apply our domain knowledge to building a reward function that would take us to the top. Our analysis of the racing domain provided three main research paths:
- Best Speed per Turning Angle
- Constant Lap Score
- Chase Best Lap
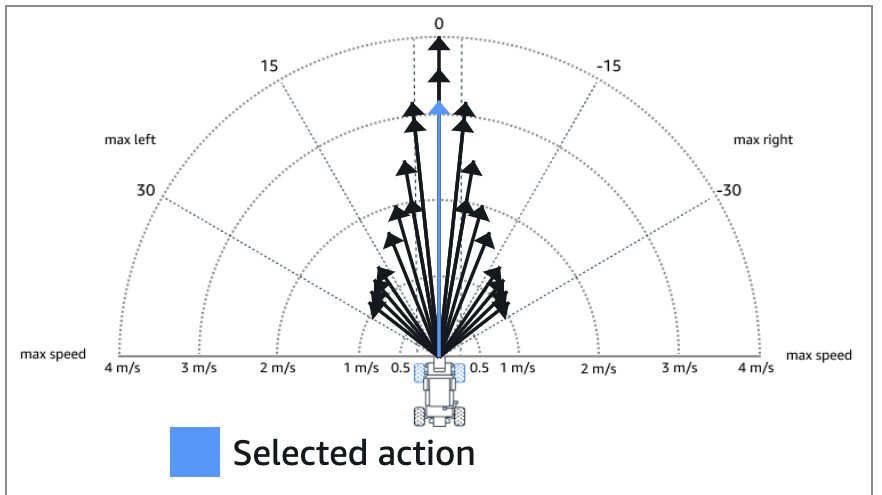
Best speed per turning angle
While building the optimal driving line solution, we noticed that the speed was always the same for any given turning angle as long as the acceleration (or deceleration) was within a small window. This provided inspiration for the first strategy; compute the optimal speed for any given turning angle and combine this with the steer-to-centerline strategy to force the model to learn to drive faster.
The results of testing this strategy were encouraging—offering faster laps overall, but the strategy did not converge. Convergence here means completing laps faster and faster until it can no longer improve.
Analysis suggested that the same problem seen with Steer to Centerline existed for this strategy—the per-step reward was tilting the balance toward ever-slower speeds to gain a higher overall score. Several attempts were made to scale the reward according to speed, but none of these attempts converged without constantly tweaking the hyperparameters.
Constant Lap Score
In an attempt to correct for the per-step reward, our next strategy ‘Constant Lap Score’ assigned a total score for completing a lap (eg. 1000 points), regardless of the number of steps taken. Thus, slow or fast, the model could never achieve more than 1000 points for a lap. This allowed the scaling parameters for speed or progress to tilt the training toward faster laps. Although this was the first strategy to converge successfully, and was competitive with other new pro-circuit participants, we were unsatisfied with the final performance.
Chase best lap
It occurred to us that the optimal driving line could be ‘discovered’ by the car automatically if we could lead the training in the right direction. This led to our final strategy, ‘Chase Best Lap,’ where the model’s location, speed, and steering was recorded at every step and saved if the lap completion time was lower than any prior attempt. Thus each run, step-by-step, the model’s reward was directly proportional to how closely it mirrored the current best lap.
Due to randomness in starting location, simulation jitter, and model variances, the car never exactly matches its previous lap, often coming in just under or just over the best time. Our strategy leverages this variance, capturing each new speed record to use as the new training target. This was the nudge it needed to start the self-improvement cycle.
Finally we had a strategy that converged optimally!
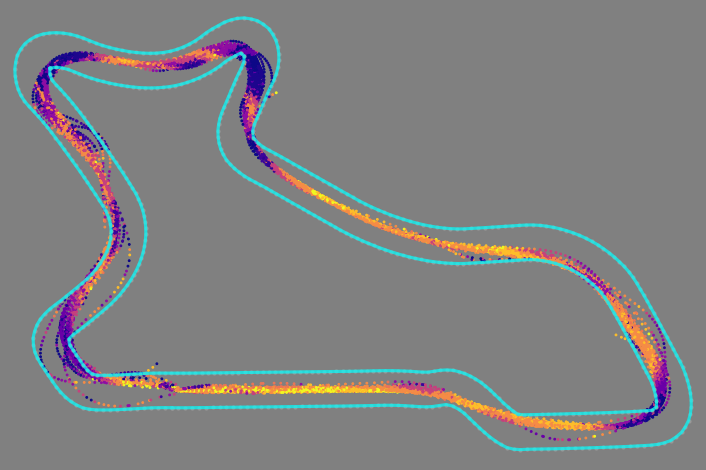
A universal reward function
One last problem persisted, the kind of annoyance that irks professional developers and spurs them to greater achievements: we had to manually switch the training of new models from an early ‘Steer to Centerline’ strategy to the late-game ‘Chase Best Lap’ strategy.
This burdensome task meant carefully watching the metrics of each new model to catch it before it began the eventual decline under the early strategy, then set up a fresh training run, and importing the partially-trained model to continue its training under the late strategy.
Since we were running in the pro-circuit now, we also needed a strategy for tackling the other two challenges: Head-to-bot and Object avoidance.
Ideally, we wanted a ‘Universal Reward Function;’ one which could be trained from scratch to convergence on any track under any challenge parameters to produce a winning model every time.
Success would mean we had “solved” the DeepRacer challenge once and for!
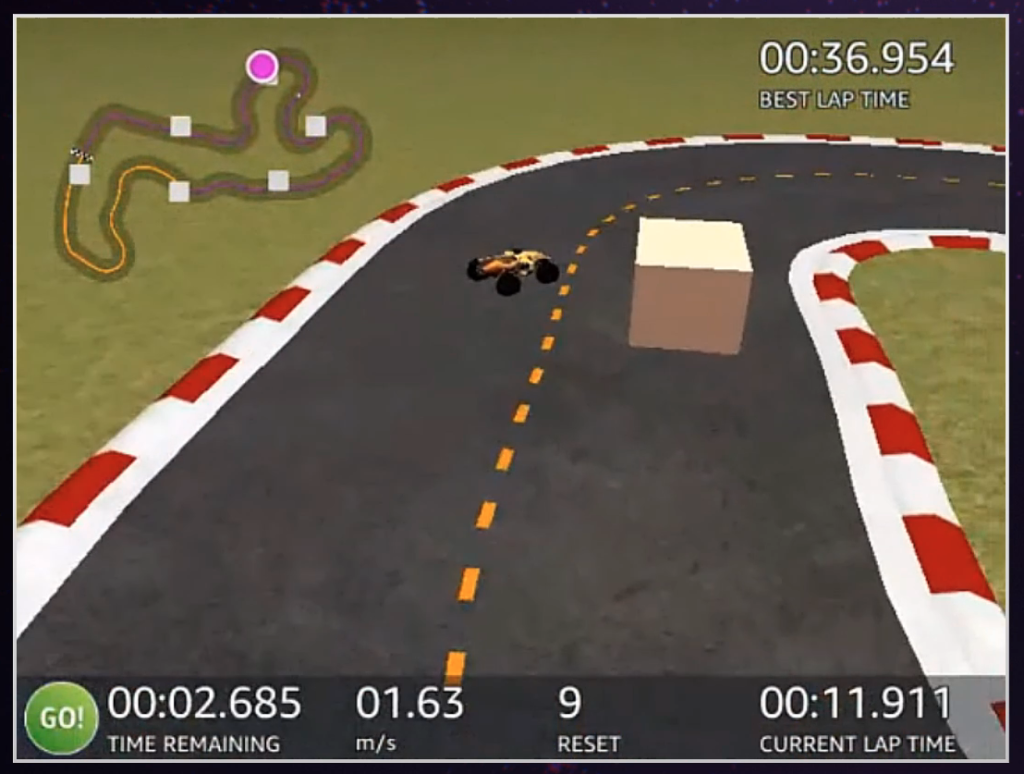
Avoiding objects
First, we needed to tackle the object avoidance problem. There was a dearth of information about successful object avoidance strategies in the community, clearly a closely-held secret among the top competitors. AWS supplies an example object avoidance reward function, which we found to be inadequate to use as a foundation for a top-performing racer.
Upon reflection we realized that only one algorithm had the ability to avoid dynamic objects: Steer to Centerline. By shifting the definition of “centerline” when the car was near an object, we could train the car to change lanes as objects approach, returning to the centerline after passing them. The hack was simple and robust, working for both head-to-bot and object-avoidance, including dodging moving objects in hairpin turns and S-curves!
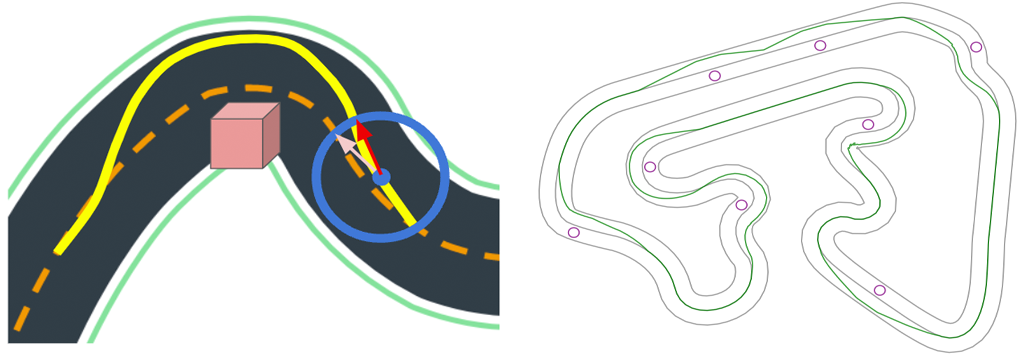
Combining the Strategies
Finally, we had the solution. Start with Steer to Centerline (augmented with object avoidance) until laps were completed consistently, then shift to Chase Best Lap relying on a gradual decline of the object avoidance reward to be compensated by the maturing model parameters.
To enact this solution we record the number of completed laps in a sliding window of 100 trials as the ‘lap completion rate.’ The two reward functions are continuously computed, and their contributions combined according to the current lap completion rate. Low completion rates lean toward Steer to Centerline, while high completion rates lean toward Chase Best Lap. To ensure Chase Best Lap is scored higher (and thus more desirable to the model), an additional scale factor is applied to that reward.
This combined strategy proved successful, offering a single reward function that converges for all challenges under a wide range of hyperparameters using only a single training run.
We solved the DeepRacer challenge!
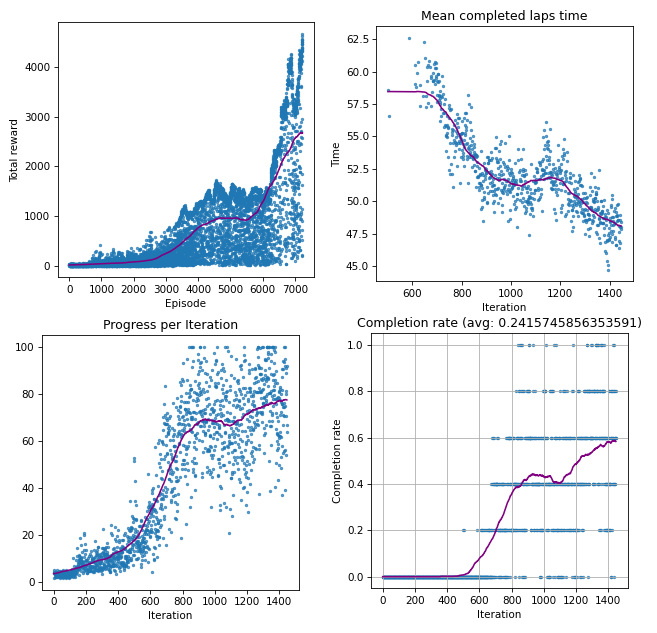
Training challenges
Much of the final two months were spent attempting to train continuous-output models. We were never entirely satisfied with their performance. Even though it trained from scratch consistently and produced converging lap times, the lap times were not yet competitive. It would take too much of the remaining time to attempt to optimize these models with no certainty of success. Meanwhile, discrete-output models seemed to skyrocket in performance with no tweaks.
Ultimately, we had to abandon continuous models and return to discrete steering angles for the final race. These issues are likely solvable with additional experience, training time, or other tweaks, but we were unable to pursue them. This lost training time proved to be our downfall.
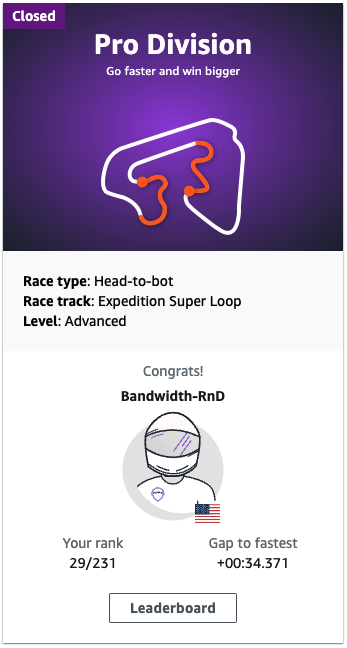
At this point, the end of the season was fast approaching and we only had a few weeks to train a final model. Another developer was brought on to continue training the best-available model, while tweaking runner-ups to improve performance. In parallel, our primary developer worked to train a model that might succeed at the object-avoidance challenge. Object avoidance is the challenge round, given only to the Top 16 racers of the pro-circuit each month. The winner of the challenge round gets a free ticket to re:Invent, or AWS credits worth many thousands of dollars.
Unfortunately, in the time remaining we were unable to pierce the top decile. Since this was the last race of the season, the year’s best competitors turned out to vie for the last ticket to re:Invent. Our final placement (29th of 231—the top 13%) was among other strong competitors with a similar number of races under their belt.
We consider this a successful showing for a new pro team!
Conclusion
Bandwidth’s R&D team enjoyed the DeepRacer competition, regularly reporting our standing at developer all-hands, and giving technical presentations of our ongoing work at monthly Lunch & Learns. Part of R&D’s mission is to raise awareness of valuable new technology, such as machine learning, and find opportunities to apply it for the benefit of Bandwidth’s customers.
Many cross-team discussions bloomed around potential uses for ML as developers on other teams learned the strengths and weaknesses of this unfamiliar technology. We are likely to continue promoting (and competing in) DeepRacer as an introduction to machine learning for the Bandwidth developer community. Currently, we are discussing the formation of multiple Bandwidth teams for interdepartmental competitions. If you’d like to be part of one of these teams, take a look at the open roles in our R&D team or the wider software development group.
Having achieved a high placement, we were awarded a physical DeepRacer car and built a track for real-world racing!
But that’s a story for another post…