Your contact center is the frontline of your customer experience—when it’s down, your business feels it immediately. Building resilience isn’t optional; it’s essential.
Read on for practical strategies to build a contact center foundation so strong it stays steady no matter how much you grow or change.
Let’s start with you. That bubblewrap of access controls and the dreaded annual infosec training might feel secure. But are you really taking the steps necessary to protect against contact center risks?
Drawing on insights from over 3,000 customers—both CCaaS providers and the enterprises that use them—our contact center experts uncovered top fears and the essential checks you need to mitigate them.
Network reliability
Do you have failovers for internet providers, routers, and SD-WAN setups across locations?
Are your voice and data networks kept separate and monitored individually so that problems in one area don’t affect the entire contact center?
Do you regularly test switching between main and backup voice/data paths (including SIP trunks) using real traffic to make sure failover works?
Telephony and SIP resilience
Do you bring your own carrier and get prioritized help during a network issue?
Does your carrier offer superior uptime metrics, within the range of 99.999% to 99.995%?
Does their network infrastructure offer redundancy and network failover options?
Does your provider have the ability to activate network failovers and handle your peak loads?
Do your providers offer global nomadic emergency solutions to support emergency regulations?
Platform and application resilience
Is your core contact center platform (on-prem, cloud, or hybrid) architected with high availability (HA), automatic failover, and geographic redundancy?
Do you have documented recovery procedures and tested RTO/RPO for critical systems like ACD, IVR, CRM, and workforce management tools?
Can your applications run in active-active or active-passive disaster recovery setups to stay up during partial or large network failures?
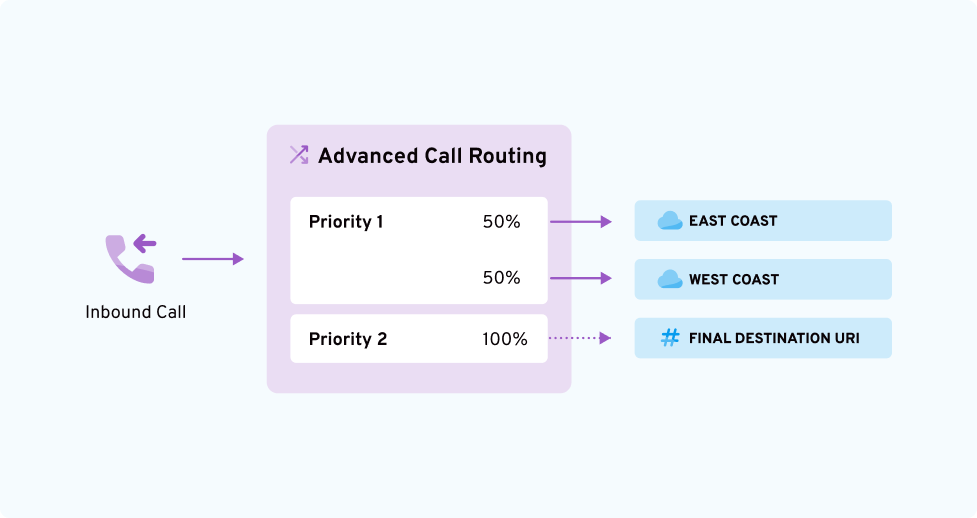
Can you optimize call loads easily across multiple carriers or shift your entire call load to your backup carrier?
Scalability and load management
Can your platform automatically scale to accommodate call traffic bursts from seasonal demand, campaigns, or unexpected incident spikes?
Are licensing models and cloud capacity flexible enough during crisis or recovery events?
Can you track call status and dropped calls in real time to dynamically manage call routing?
Does your SIP provider offer multi-tenant SIP trunking with pay-for-what-you-use billing and real-time reports to help scale intelligently?
Fraud and abuse prevention
Do you monitor for indicators of fraud such as robocalls and take automated action when detected?
Are agent desktops and call-handling processes set up for internal fraud prevention, like screen masking, and strict access controls?
Does your SIP provider maintain real-time alerting and reporting on usage anomalies and fraud attempts at the voice network and application levels?
Can you set limits on call volume, restrict destinations, or block calls to certain regions to reduce fraud risk?
Does your fraud system connect with your SIP trunking billing to quickly cap usage or lock accounts if suspicious activity is detected?
Security and access controls
Are all endpoints, agents, and admins authenticated through secure methods (e.g., MFA, VPN, Zero Trust) with access controls based on least privilege?
Is call data—including voice recordings, chat transcripts, and customer data—encrypted using industry-standard protocols?
Do you conduct regular penetration testing and vulnerability scanning across your contact center systems, and platforms?
Does your SIP provider have robust security mechanisms such as carrier-grade Session Borders Controllers in place?
Does your SIP provider control access to your SIP management settings and allow audit logging for troubleshooting?
Workforce and agent continuity
Do you provide agents with secure remote work capabilities—including softphones, VDI, or browser-based platforms—with QoS monitoring and IT support?
Are agents trained for continuity procedures, including platform outages, telephony failures, or sudden transitions to remote operations?
Do you support omni-channel fallback (e.g., switching from voice to SMS or email) when one or more channels see an outage?
Monitoring, reporting, and insights
Do you have a central dashboard that shows real-time health of your voice, platform, network, and agents, with smart alerts for key issues and unusual activity?
Do you use automated tools for call tracing, quality checks, and SLA monitoring for troubleshooting across vendors?
Are major incident alerts integrated with your NOC, SOC, and service desk workflows for rapid response and documentation?
Business Continuity Planning (BCP) and Disaster Recovery (DR)
Are you able to test call loads to different carriers and plan to respond fast during a crisis?
Do you maintain a formal, tested business continuity plan (BCP) that includes roles, escalation procedures, contact trees, and alternate workflows for key disruptions?
Do all key systems (SIP trunks, CRMs, contact platforms, IVRs) have defined and clear documentation of ownership during a failover?
Vendor and third-party dependencies |
Do your SLAs with platform providers and carriers include explicit uptime guarantees, support response times, incident priority assignment options, and DR obligations?
Are third-party integrations built with fault-tolerant patterns like retries or graceful degradation during outages?
Do you have exit strategies and vendor risk reviews in place to activate backup providers/routing paths during long outages?
Interoperability and failover
Does your SIP platform support seamless interoperability with major contact center platforms (e.g., Genesys, Five9, Amazon Connect, Webex) through tested carrier integrations?
Can you offer backup trunking paths, disaster recovery (DR) trunks, or hybrid configurations ( cloud + on-prem) to reroute calls during outages?
Is your platform regularly tested for disasters like DNS attacks, carrier failures, or DDoS, and can customers run disaster recovery drills?
Governance, audit, and compliance
Is your contact center regularly audited for compliance (e.g., PCI-DSS, HIPAA, GDPR), and does your resilience planning reflect all regulatory mandates?
Do you maintain up-to-date documentation and runbooks for critical contact center systems, network topologies, and escalation workflows?
Are audit logs preserved and reviewed for key events—admin access, config changes, failovers, fraud attempts—to ensure accountability and forensic readiness?
Does your carrier support your compliance processes across your global business?
Did you check all the boxes? If yes, read on just to humor us. If not, you need the primer on contact center resilience below.
We’ve prioritized the core competencies required to protect your contact center before leading to future-proofing strategies. First, let’s zoom out and refresh you on what’s at stake with an unguarded customer service operation.
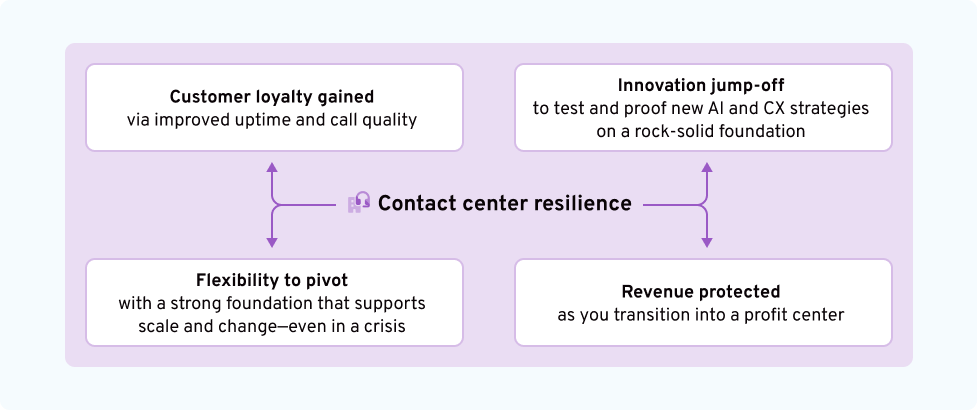
Become resilient to springboard CX wins
You aren’t just fighting to protect your customers, you’re establishing a crisis-proof brand reputation. Dropped customer service calls and unreachable contact centers can damage customer loyalty—often in irredeemable ways—with competitive options waiting on your heels.
By building resilient contact center communications, you galvanize your position as a reachable and reliable brand. The prize? You get to keep the customer base you earned—and grow it.
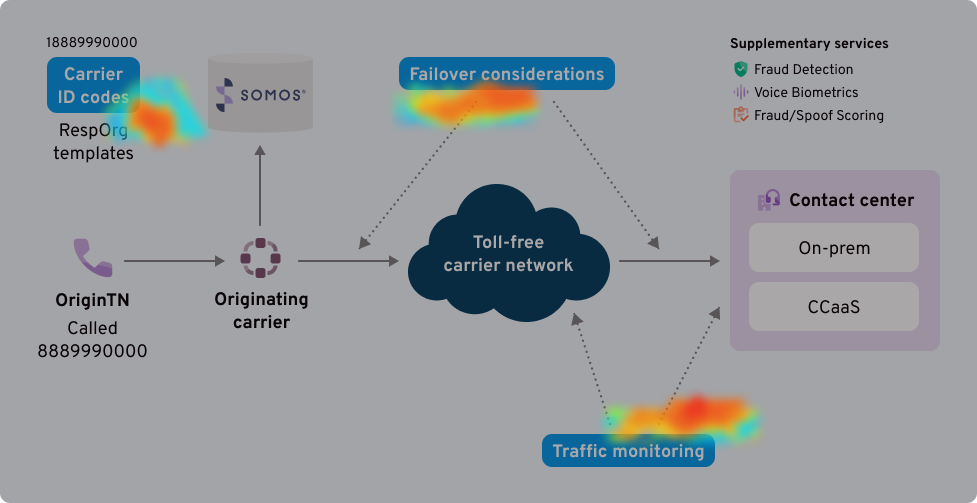
The toll-free crisis heatmap
Your toll-free setup requires you to make resilience decisions on multiple fronts. The hotspots here depict the pivotal places where your decisions either make you highly susceptible to outages or invincible to them. Let’s walk through them.
What works?
Monitoring your own traffic offers you a view of your network alone. What about upstream or downstream outages that could affect your calls?
What elevates CX?
You can rely on your carrier to get comprehensive outage insights into your entire market. For instance, Bandwidth Insights customers rely on our carrier-grade insights, gathered across all of our customers, alongside their own traffic monitoring to stay on top of network threats
Most companies use advanced traffic monitoring to spot anomalies or outages in their networks. If you automate this step with tools like anomaly detection and automated alerting, you can respond faster to potential outages.
What works?
Most companies operate this way. They get an outage alert and redirect calls away from problem areas or vendors until the issue is fixed. It’s smart, but it’s not enough.
What elevates CX?
You’re still being reactive—not responsive.
Your carrier can do more. Imagine having:
Multi-carrier routing optimization
Automatic routing adjustments before calls start dropping
Seamless failover to backup routes whenever needed
Picture this:
You have a dedicated employee (or team) monitoring network alerts around the clock, ready to reroute toll-free traffic whenever an issue pops up.
What works?
Being your own RespOrg might seem like a smart move for control and cost savings, but it requires you to have staff for 24/7/365 traffic monitoring and template management. Have you considered the opportunity cost?
What elevates CX?
There are hidden overheads to being your own RespOrg that come with managing your own toll-free setup. More importantly, any blind spots, especially in the components underlying your carrier network, can lead to downtime and inefficient call routing, disrupting daily operations and ultimately costing you more than you saved.
Before risking your toll-free strategy, weigh the pros and cons of being your own RespOrg versus using a trusted provider. The right provider can offer you control without the rigorous responsibility of managing your toll-free.
You will often come across advice to become your own Resporg (Responsible Organization) to assume control of managing your own toll-free, including call routes and purchasing toll-free numbers directly from SOMOS in order to cut out the middlemen.
What works? Failovers: Ask the tough questions. Do you switch to backup routing options almost instantly when part of your network goes down? How fast does that happen? Can your backup handle the full volume of calls?
Or put another way, if and for how long will your customers feel your CX take a nosedive during a routing outage? Relying on unused, untested backups only makes things worse.
What elevates CX? Disaster Recovery: Imagine a disaster knocks out several parts of your communication system—as it often happens. Do your backups have backups? A disaster recovery solution will temporarily reroute your traffic through a secure alternative while you pinpoint the problem and restore your main network. Ideally, this failover happens smoothly and quickly, bypassing the original issues without disrupting your service.
Those were your key considerations to maintain a high-uptime contact center. Next up: resilience solutions.
What’s your response when network issues eventually win? The goal is to steer your contact center through, unscathed.
Contact center resilience must-haves
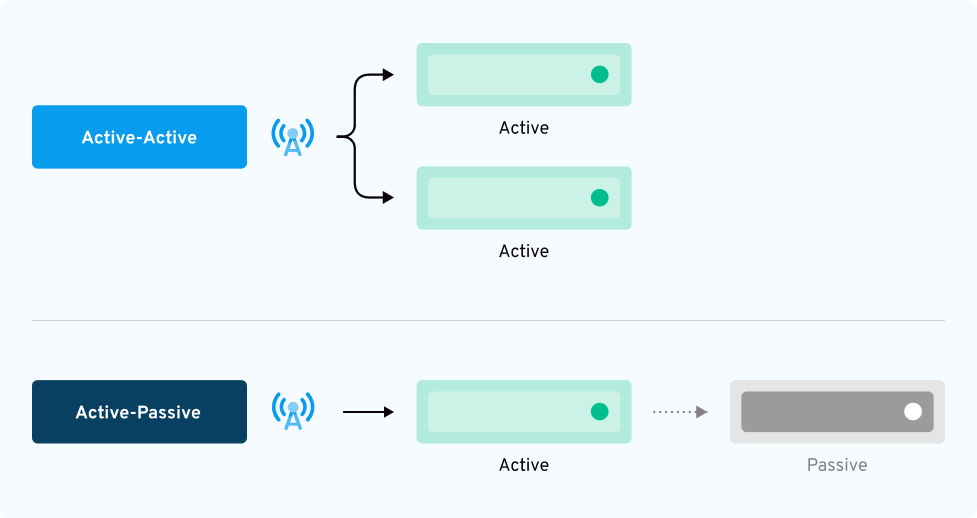
Don’t just failover, pass over seamlessly, with Active/Active architecture
In 2023, major network operators in both the UK and Australia faced major outages. In the UK, this put the concerned carrier’s emergency calls out of commission, affecting approximately 14,000 emergency calls over a 10.5-hour period.[1] For the Australian network operator, a 14-hour outage took down 10 million customers and had 2,145 people unable to connect to emergency services.[2] This is with failovers being available in some capacity.
So what could’ve helped?
An Active/Active toll-free network architecture.
This type of network setup runs traffic simultaneously across multiple carriers/routing paths, ensuring continuous uptime and seamless call handling during an outage. In contrast, an Active/Passive architecture has one network in use with other network(s) available on standby for failover.
What does an Active/Active network architecture look like?
Active/Active architecture can deliver unmatched benefits:
The distributed nature of the Active/Active setup provides inherent fault tolerance, as the system can withstand individual network outages without service disruption.
If one network fails, the remaining active network can continue to serve requests, ensuring continuous availability of services with minimal or no downtime.
Active/Active network systems have multiple carrier interconnects. As call volumes increase, more call load can flow through different carriers.
Lock in contact center resilience with BYO-Carrier
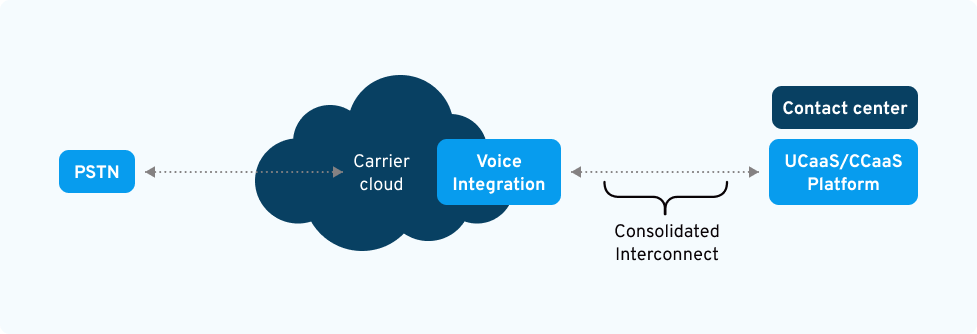
How much control do you have over your carrier relationships and call routes? When a network outage hits, can you get direct support from the affected carrier? BYO-Carrier solves that by unbundling your CCaaS from your toll-free carrier.
When you Bring Your Own Carrier, you choose your preferred carrier to power voice, messaging, and emergency services for your preferred CCaaS platform. Essentially, you’ll be one hop away from both your CCaaS platform and the underlying carrier.
While cost savings remain the top benefit of Bringing Your Own Carrier (for 58.21% of BYOC adopters), 37% report higher quality telephony.[3] It’s hardly surprising that over 53% of enterprises now BYOC. Increasingly, enterprises are turning to BYOC to build robust contact centers by putting control in the right place—their hands.
Move to or between CCaaS platforms easily, without compromising your network resilience. Or even retain a hybrid configuration, while managing the same vendor for both.
BYOC lets you distribute your telephony risk by prioritizing a trusted provider that offers multi-carrier redundancy.
Outages happen. With BYOC, rerouting traffic is fast and flexible—no begging your provider for action.
You’re not tied to inflated carrier contracts. Optimize routes and costs on your terms, not theirs.
Reinforce resilience with voice insights and analytics
You’ve built a great stack with reliable back-ups. Your CX is ready for take off.
Should it fly blind in the face of possible disruptions?
No savvy contact center goes without voice insights. By analyzing real-time call metrics, CX leaders can quickly identify issues, optimize performance, and continue to offer a consistent customer experience during peak demand or disruptions.
Faster troubleshooting: Real-time call data helps identify problems like dropped calls or congestion early, allowing for quick fixes before they impact customers.
Improved decision-making: Access to detailed call metrics enables leaders to make informed decisions about resource allocation and system upgrades.
Enhanced performance monitoring: Continuous tracking of call quality and volume ensures the contact center can adjust dynamically to changing demands.
Fast-tracked risk management: Insights into calling patterns can reveal potential risks, such as fraud or network failures, enabling preemptive action to maintain service continuity.
Contact center resilience scorecard
You’re taking the right steps to build a contact center that can weather any storm—you’re actively strengthening your defenses. Are you sure those protections are actually working as intended and delivering the resilience you expect?
Use this quick scorecard to monitor and assess your contact center’s overall resilience posture. It’ll give you a clear picture of your strengths and areas where you might still need to level up—because a little extra reassurance goes a long way when your customers are counting on you.
1. System uptime and availability
Metric
Definition
Expected result
System uptime (%)
Percentage of time the platform is operational
≥ 99.99% at the very least (≈ <5 min downtime/month)
Service interruption frequency
Number of partial/full outages per month or year
0–1/month, <5/year
Mean Time to Recovery (MTTR)
Avg. time to restore service after failure
<15–30 minutes
Failover activation time
Time to reroute to backup systems or carriers
<60 seconds for critical services *Exceptions apply
2. Redundancy and failover effectiveness
Metric
Definition
Expected result
Multi-carrier readiness (BYOC)
# of active SIP/PSTN routes
2+ providers
Carrier failover success rate
% of failovers without dropped calls
>99%
Geographic failover coverage
# of active regions for routing
2+ regions
Cloud-to-cloud fallback latency
Time to reroute between clouds
<3–5 min
3. Network and infrastructure performance
Metric
Definition
Expected result
Network latency (RTT)
Round-trip time for voice/data
<150ms voice
Packet loss
% of packets lost in transit
<0.5%
Jitter
Variability in packet timing
<30ms
Bandwidth redundancy
Backup connection capability
Full failover path
4. Operational and human resilience
Metric
Definition
Expected result
Agent availability rate
% of scheduled time agents are logged in
>95%
Agent cross-skill coverage
% of agents trained for multiple queues
>75%
Agent readiness during disruptions
% of agents able to work during failover
>90%
Business continuity plan tested
Time since last live BCP test
<6 months
5. Monitoring, alerting, and response
Metric
Definition
Expected result
Monitoring coverage
% of systems monitored in real time
100% critical
Alert response SLA compliance
% of alerts resolved in SLA
≥95%
Incident RCA rate
% of incidents with root cause completed
100% Sev-1/2
Proactive incident detection rate
% issues caught before users report
≥80%
6. Security and regulatory resilience
Metric
Definition
Expected result
Multi-factor authentication
% of agents with MFA enabled
100%
Data loss during outages
# of records/calls lost
Zero
Compliance readiness
Adherence to PCI, HIPAA, DORA, NIS2
Fully certified/compliant
Audit trail completeness
% of events/actions logged
100%
7. Customer experience resilience
Metric
Definition
Expected Result
Call drop rate during failover
% of calls dropped during reroute
<0.2%
Customer wait time during incidents
Wait time deviation during outage
<10% increase
Self-service deflection rate
% resolved via IVR/chatbot during outage
>40%
Post-outage CSAT recovery time
Time to restore pre-outage CSAT
<72 hours
How did you score? Feeling shaky? Get help from veteran contact center experts here. By closely monitoring metrics like system availability, network performance, failover readiness, and customer experience, organizations can create a contact center that not only survives disruptions but also adapts instantly. A resilient contact center doesn’t just bounce back from outages—it provides continuous service, keeps customer trust, and strengthens brand reliability, irrespective of the conditions.
It’s worth remembering…
Building a truly resilient contact center is a marathon, not a sprint. And it’s the first step in turning customer excellence into a profit center. Because resilience isn’t just tech—it’s trust. Build it, and your customers will never know the difference when disaster strikes. But your competitors will.
Ready to transform downtime into uptime and deliver consistent, reliable service no matter what?